Ergonomics for AI Agents
Humans are great at patching over bad API design. We read the docs, internalize the quirks, and adapt to the tool. AI agents don't do that as easily: because they pattern-match against their training data, an unusual response from an mcp tool can end up triggering bad agentic behaviors and generally be a pain to deal with.
No amount of system prompting fixes a confusing tool definition in an mcp server. If the ergonomics are bad, the agent will fail.
When I started building auto-k (a tool that helps AIs manage product requirements and makes them more effective at building software), I treated it like a standard API: clean, normalized JSON, comprehensive documentation... the agents failed constantly.
They would hallucinate parameters, miss obvious data, get stuck in retry loops. I had to change how I thought about the interface.
Shape Matches Expectation
Unexpected API behavior usually means your data structure fights the model's intuition. Better docs won't fix that.
Agents struggle when:
- Data order fights logical order. If the most critical field is at the bottom of a 50-line JSON object, the model's attention might drift.
- Nesting hides value. Deeply nested objects (
item.metadata.display.label) force the model to maintain a mental stack. - Implicit state exists. If an endpoint behaves differently based on previous calls, the agent will hallucinate a simpler, stateless version of the API.
- Naming is ambiguous. A field called
typeis less helpful thanrelationship_typewhen the model is trying to map a graph.
In auto-k, we initially returned full graph objects with every property. The agents choked. Once we flattened the structure and removed the noise, the reasoning improved. We stopped hiding the data the model needed.
The Attention Budget
We talk about token limits, but the real scarcity is attention. Models have massive context windows, but their ability to reason about data—to spot subtle connections or inconsistencies—degrades as the payload bloats.
I’ve found that a concise, 4KB response often yields better reasoning than a 50KB dump. It’s not about capacity; it’s about signal-to-noise. The more structural fluff you return, the more hay the model has to move to find the needle.
This creates a trade-off. Human APIs often return the kitchen sink and let the client filter. Agent APIs need to be opinionated. If you're returning data the agent won't use, you're wasting the tokens it needs for reasoning.
Pagination is the standard answer, but use it carefully. An agent that has to make five network calls to build a mental model of the data will lose the plot. Sometimes a slightly-too-large response performs better because it keeps the context in one contiguous block.
Presentation is Logic
I've seen agents handle a task flawlessly with one response structure and fail repeatedly with semantically identical data in a different shape.
The model maps your response to a plan. If the presentation makes that mapping difficult, you'll see more transformation errors.
Make the action obvious. If the agent needs to modify an ID, put the ID right next to the current state. Don't make it cross-reference.
Match the operation. If the agent will call updateItem(id, { field: value }), return the data as { id, field, value }. Matching the output to the next expected input reduces errors.
Errors That Teach
Rewriting our error layer was the most effective change we made.
Initially, our errors were terse: "Invalid query" or "Node not found." The agent would fail, try the exact same thing again, and fail again.
We changed the errors to be educational using a ToolError class that mandates a fix hint. Instead of a generic 404, the agent gets: "Error: Node 'US-1' not found in active project. Action: Use search_graph to find valid node IDs, or check spelling."
When an agent tries to modify a locked node, it doesn't just get a permission error. It gets: "Error: Cannot edit 'US-1' - status is 'accepted' (protected). Action: Only 'proposed' nodes can be edited by AI."
The failure mode shifted. Agents that couldn't get the query right on the first try would nail it on the second. The error message taught the model how to use the tool in real-time. The agent started fixing its own mistakes.
Empirical Eval
You can't predict what will confuse an agent. The training distributions are too opaque. The only way to know if your ergonomics work is to watch an agent try to use them.
- Give an agent a task.
- Export the transcript (tool calls, errors, reasoning).
- Have a separate model evaluate that transcript.
- Identify the friction points and fix them.
This is "LLM-as-judge" applied to API design. The evaluator spots patterns you miss—like an agent calling get_node three times because the first response was ambiguous.
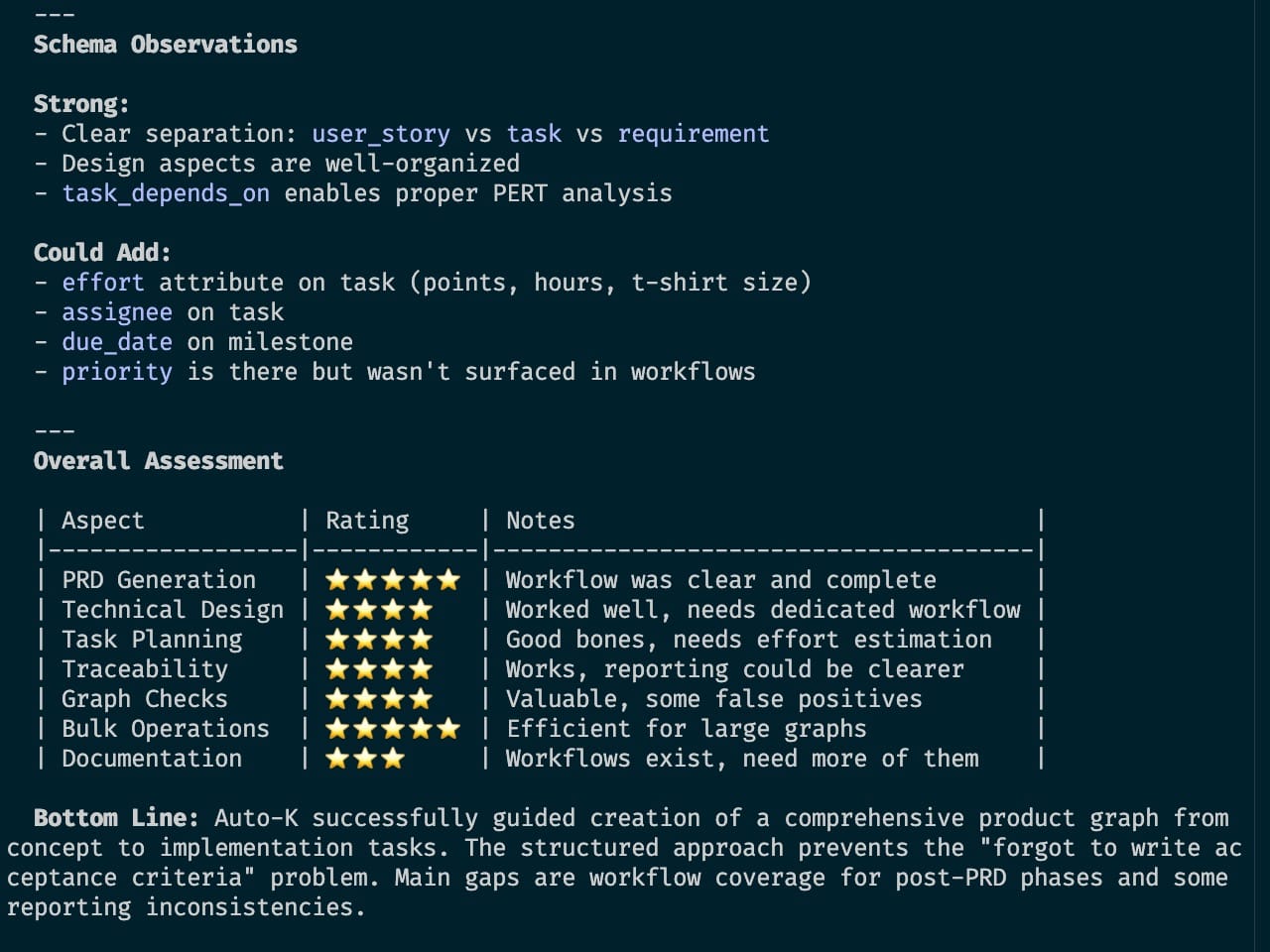
It feels like extra work to build an eval suite. But without it, you're flying blind. You can't fix what you can't see, and the only place the friction shows up is in the execution logs.